We are delighted to announce the publication of our team-authored article “Developing a classification model for graphic devices in early printed books” published in Studia Neophilologica (open access, online, ahead of print).
In the article, we discuss our methodology and introduce our model for classifying graphic devices in historical materials. This classification is the foundation for our ongoing quantitative survey of the use of graphic devices in early modern books.
We also discuss previous taxonomies and models which have been presented for classifying graphic elements in various fields, ranging from geography to semiotics and education psychology, for example. We explain why none of these existing models is suitable for our EEBO and ECCO materials, and what steps we have taken to devise our own classification model.
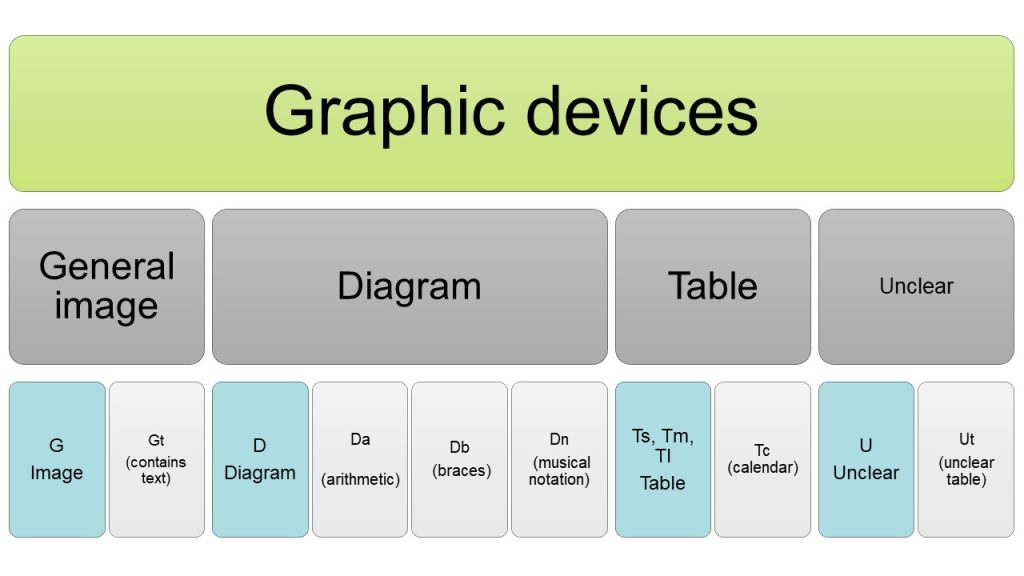
In short, we divide graphic devices in three main categories: general images (G), diagrams (D), and tables (T). All categories have subcategories for certain distinctive types, such as calendars (Tc) and musical notation (Dn). Additionally, any unclear items (unclear due to reasons of damage, or because they combine characteristics of more than one category, for example) are placed in a separate category (U). Tagging unclear items separately allows us to exclude them from the quantitative analyses while keeping them easily accessible for further examination in qualitative research articles.
Ruokkeinen, Sirkku, Aino Liira, Mari-Liisa Varila, Otso Norblad, and Matti Peikola. “Developing a Classification Model for Graphic Devices in Early Printed Books.” Studia Neophilologica, 2023. https://doi.org/10.1080/00393274.2023.2265985.

