Almost exactly two years since the first EModGraL workshop it was time for the research team and our collaborators to gather again in Turku for a second full-day workshop, which took place in the newly renovated Arcanum building (and on Zoom) on Friday 3 November. The day was full of invigorating discussions on different kinds of graphic devices and their research.
We followed the 3-session format established in the first workshop. The first session was devoted to questions related to data. We discussed the EModGraL data gathering process and our finalised typology for classifying graphic devices, recently published. The second important topic to discuss was the challenge of combining our data collected from the two databases, EEBO and ECCO, as each database provides a slightly different set of metadata with which we operate. Thirdly, as we are planning to open our research data for other researchers after the project, we discussed some of the practical, legal and ethical questions that need to be taken into account.
Workshop participants in the meeting room ‘Luoma’ in Arcanum.
The second session after lunch was reserved for discussing draft versions of two in-progress research articles. Aino Liira and Wendy Scase presented their draft of an article on metatext concerning tabular displays. Sirkku Ruokkeinen and Outi Merisalo presented their work on graphic devices and typographical practices in early modern English military manuals.
In the third session, Matti Peikola (et al.) and Mari-Liisa Varila presented on-going research, after which some time was reserved for general matters and wrapping any loose ends. In practice, these two halves of the session were somewhat intertwined and discussion remained lively until the end.
Our final, important topic to discuss was the graphic literacies conference we’re planning for 2025. More information will follow shortly!
In the article, we discuss our methodology and introduce our model for classifying graphic devices in historical materials. This classification is the foundation for our ongoing quantitative survey of the use of graphic devices in early modern books.
We also discuss previous taxonomies and models which have been presented for classifying graphic elements in various fields, ranging from geography to semiotics and education psychology, for example. We explain why none of these existing models is suitable for our EEBO and ECCO materials, and what steps we have taken to devise our own classification model.
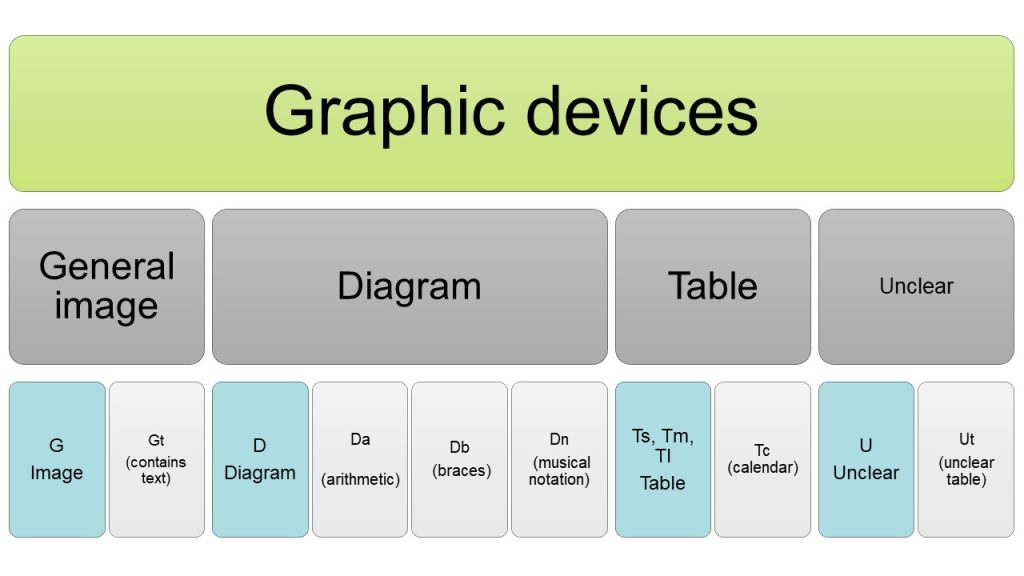
The EModGraL classification model. Visualisation: MLV/EModGraL
In short, we divide graphic devices in three main categories: general images (G), diagrams (D), and tables (T). All categories have subcategories for certain distinctive types, such as calendars (Tc) and musical notation (Dn). Additionally, any unclear items (unclear due to reasons of damage, or because they combine characteristics of more than one category, for example) are placed in a separate category (U). Tagging unclear items separately allows us to exclude them from the quantitative analyses while keeping them easily accessible for further examination in qualitative research articles.
Ruokkeinen, Sirkku, Aino Liira, Mari-Liisa Varila, Otso Norblad, and Matti Peikola. “Developing a Classification Model for Graphic Devices in Early Printed Books.” Studia Neophilologica, 2023. https://doi.org/10.1080/00393274.2023.2265985.
A personal anecdote from a freshly graduated English major | Text: Elina Parkkila | Featured image: Debby Hudson (via Unsplash)
A well over a year ago, I was in the stage of my studies where it was time to prepare for the MA thesis. I was facing the same questions many students have at that moment. What is a good topic? Should my topic reflect on my future plans? What kind of topics interest me? Fortunately, I was lucky to stumble upon a topic that served to feed my two main interests in life, the English language and history.
Prior to my thesis seminar, I did a course called Late Modern English project. As the name suggests, it introduces students to the period of late modern English from the 18th to the beginning of the 20th century. I found the overall topic of the course interesting, but one portion of the material piqued my interest the most, grammar-writing. I decided to focus on this new topic I “discovered” for the essay-portion of the course. For my essay-writing, I picked a few 18th–century grammars and compared them to each other to see how they managed to cater to their audiences. In the essay, I made a small observation about how some of the grammars used what I referred to as “graphical content” and some did not. I constituted graphical content to be any form of break from traditional style of writing, which was supposed to be viewed visually through graphicacy rather than reading it as a text. Some examples of graphical content in 18th–century grammars were word lists, exercises, and atypical spacing of text. This observation was a blessing in disguise, as my course professor pointed out how this could be a possible thesis topic. I will not turn down a good suggestion, so I decided to venture further into the topic.
Graphical content in 18th-century grammars
For my MA thesis, I decided to analyse how different 18th–century grammars used graphical content for teaching grammar. I cross-referenced Eighteenth Century Grammars Online (ECEG) and Eighteenth-Century Collections Online (ECCO) for grammars that were written both by women and men. I was interested to see how the gender of the grammarian as well as the perceived target audience could influence the results. It led me down an interesting path to be educated on the overall history of grammar-writing in England, the history of grammarians, and the development of graphicacy.
Even to this day, almost a year after writing my thesis, I find the topic of grammar-writing highly intriguing. It was interesting to see how the societal changes and attitudes about people, the world, and languages were able to be seen in the grammars. As a woman, I was very intrigued by the research that had been done on female grammarians, who were slightly different in their approaches to teaching grammar compared to their male counterparts.
However, my analysis also proved my views to be slightly biased towards the growing demographic of female grammarians who mostly targeted their work towards women and children. Male grammarians, on the other hand, targeted their work more towards men and children. Before the proper analysis on my chosen grammars, I assumed that male grammarians were less inclined to use graphical content as a teaching tool, as their most common target demographic (men) were more likely to have received formal education on grammar. In a sense, I thought that the more educated the target demographic was, the less graphical content was used by grammarians. I proved myself wrong. Grammars targeted towards women contained the most graphical content, while grammars targeted towards men contained the second most amount of graphical content.
MA thesis writing is a multifaceted learning experience
As I am thinking about this learning experience a year later, it shows that I had a narrow view on who were a part of the new broader audiences for English grammars in the growing society of England. Sometimes checking your biases and learning from being wrong can open yourself up to an interesting analysis on how grammar-writing and teaching was viewed for different demographics.
Overall, I see the 18th–century grammars and grammar-writing as an interesting target of research, as the shifting economy and the rise of the working class created new avenues for writing and learning grammar. It makes one really think about the future of grammar-writing research, what kind of signs of our society today can be found in modern grammars?
The author is a former English student at the University of Turku. The history of the English language and history in general were the author’s key interests while studying. The author is currently working in the museum field.
Parkkila, Elina. 2022. The Beginning of Visual Grammar Learning: Analysis on the Use of Graphical Content in 18th Century English Grammars. Master’s Thesis, Department of English, University of Turku. Available online: https://urn.fi/URN:NBN:fi-fe2022091358943
September marked the halfway point of our four-year project. Let’s look back into the past academic year and see what we have been up to.
Thousands of graphic devices
We completed the sampling of the EEBO data, i.e. the years 1473-1500, 1521, 1546, 1571, 1621, 1646, 1671, and 1696. From these years, we have analysed all books printed in English that are contained in EEBO. Altogether this amounts to ca. 4,300 books and 510,000 pages! The overall number of graphic devices we have found and classified in this material is ca. 25,300. We are eager to do further statistical analyses and publish the results.
Out of curiosity, it could be mentioned that the highest number of graphic devices encountered in a single book is 1,353 devices! The book in question is Samuel Jeake’s arithmetical work Logistikēlogia, or Arithmetick surveighed and reviewed published in 16961 (the full title is monstrous enough to be hidden in a footnote). As you can probably guess, this book mostly contains arithmetical notation.
Publications…
Our team has been busy working on publishing the research results. In February, we announced the publication of Matti Peikola and Mari-Liisa Varila’s article on late medieval English calendars; in the meanwhile, another article by them, discussing reader instruction in Middle English tables and diagrams, has been accepted for publication in the Journal of Historical Pragmatics. Our team-authored article on the EModGraL classification model has likewise been accepted and is forthcoming in Studia Neophilologica. The edited collection Graphic Practices and Literacies in the History of English (with chapters written by EModGraL team members as well as collaborators) is in progress and will be submitted to the publisher later this autumn.
Our team members are currently working on articles addressing topics such as captions (Varila), braces (Peikola & team), graphic devices and paratextual matter (Sirkku Ruokkeinen & Outi Merisalo), and metatext associated with tabular devices (Aino Liira & Wendy Scase), to name a few.
…and presentations
The ICEHL-22 conference took place in the Diamond building in Sheffield.
The EModGraL team members have attended various conferences and other events to present and discuss their research. In January 2022, Aino Liira attended the first national Research Symposium for Early Career Historians on the History of Science and Learning, where she presented the results of a study co-authored with Matti Peikola and Marjo Kaartinen on ‘visual chronologies’ in Early Modern English books (to be published in the Brepols volume). Later in February, Aino and Matti also discussed this topic in a Studia Generalia lecture hosted by TUCEMEMS. In July, the EModGraL team (along with some other Turku colleagues) travelled to Sheffield, UK, for the 22nd International Conference on English Historical Linguistics. Of course, our researchers have also participated in smaller but still important events and meetings throughout the academic year. For instance, Aino and Sirkku presented their research at the Research Day of the School of Languages and Translation at the University of Turku in the spring.
Research visits, collaboration and teaching
Last autumn we were happy to host James Titterington’s two-month research visit to Turku, funded by the Turku University Foundation and the EModGraL project. The collaboration on a research article continues after his visit. Around the same time as James arrived, Aino started her three-month visit to London and the University of Birmingham.
In the spring term, we offered a team-taught course ‘Early Modern Multimodal Practices’, available for students at the Department of English and other language departments. We had a small group of students but all of them were highly enthusiastic. The course included classes on early modern printing, the use of online databases such as EEBO and ECCO, paratexts, and multimodality in different domains and genres, such as science, religion and handbooks. We also paid visits to the University of Turku Library and the Donner Institute Library where our students had the chance to see and handle rare books. Our students enjoyed these practical, hands-on sessions tremendously, and they were a rare treat for the teachers as well!
Onwards to the second half of the project
At the moment we’re looking forward to a second workshop with our collaborators, to be held on Friday 3 November. Based on our good experiences from the first workshop, we’re expecting a day full of invigorating discussions. Time will be reserved for discussing article drafts and presenting on-going research as well as discussing the current stage of our quantitative survey of graphic devices.
Plans are also underway for an international conference on the themes of graphic devices and graphic literacies in 2025 – stay tuned for more information!
Text: Aino Liira & Matti Peikola | Photos: Aino Liira
1. Jeake, Samuel. Logistikēlogia, or Arithmetick surveighed and reviewed: in four books. Viz. 1 book 1 part intergers. 2 part fractions. 2 book 1 part geodæticals. 2. part figurals 3 book 1 part decimals. 2 part astronomicals. 3 part logarithmes. 4 part coffics. 5 part surds. 6 part species. 4 book 1 part ratios. 2 part proportions disjunct. 3 part proportions continued. 4 part Æquations. Wherein the nature of numbers absolutely abstract, generally and specially contract, with their simple and comparative elements, are plainly declared, and fully handled. Every part furnished with such necessary rules, cases, theoremes, questions, observations, and varieties of operation, as principally to them belong, ... and delivered in so familiar a style, as may befit mean capacities, and if practically applied, become more than ordinarily useful both in mechanical and mathematica arts and sciences. By Samuel Jeake senior. London: printed by J.R. and J.D. for Walter Kettilby, 1696. Wing J499.
Writing an EModGraL-themed MA thesis | Text: Saara Kaltiomaa
Deciding on the topic
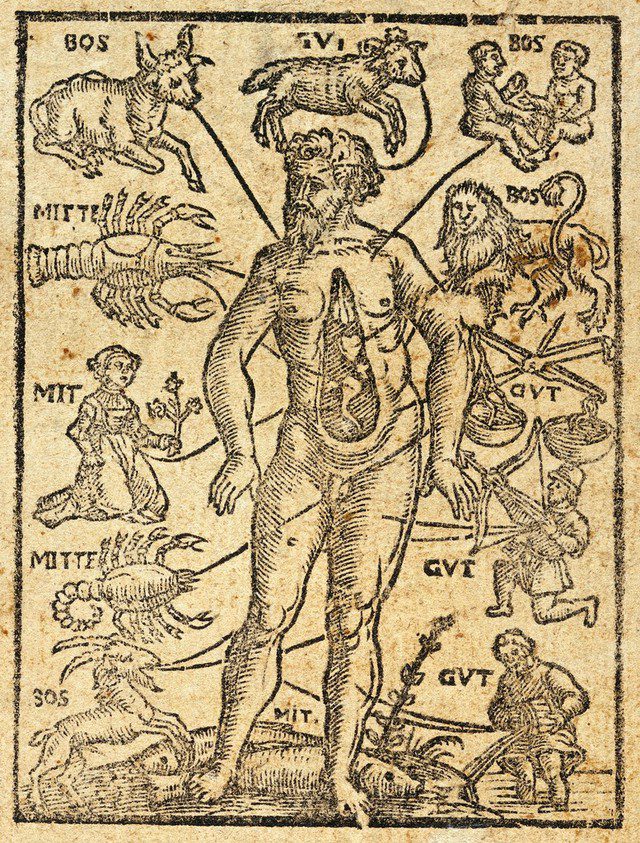
Back when I was a fourth-year student at the University of Turku I was planning on writing my master’s thesis about fluency measures and SLA (second language acquisition) related themes. But in the Spring of 2022 I took a course called Texts and Contexts 1 where I was first introduced to Early Modern Graphic Literacies. I was mesmerised by the illustrations we analysed in the classroom, and I knew I had to look further into the themes of woodcut illustrations in prints and the textual elements surrounding them, especially the Zodiac Man figure found in many Early Modern English (EModE) printed almanacks.
The lecturers, Matti Peikola and Mari-Liisa Varila (who both actually guided me through my writing process), were very supportive with my choices of themes and provided me with additional literature to help me approach the topic. We discussed that exploring the EModE printed almanacks would be a great place to start, as they can be found fairly easily in online databases. I myself used Early English Books Online (EEBO) which I found to be handy and easy to use.
Zodiac Man woodcut in the German almanack of Petrus Slovacius, Allmanach auff das 1581 jar. Breslau (Wrocław): Johan Scharffenberg, [1580]. Wellcome Collection, public domain.
Analysing almanacks
The sheer amount of the EModE printed almanacks I found was astonishing: back in the day the publication was found in basically every household. As the printing press was developed and paper slowly replaced parchment, mass producing texts became way faster. Most importantly, printed publications were more affordable to the common folk (vs. manuscripts). These printed almanacks were also written in English instead of Latin or French, which made the publications accessible to many. Not to mention the more practical size: compared to handwritten manuscripts, printed almanacks were often sort of smaller, portable versions of them.
Results
In short: I looked into the language, contents, and visual elements surrounding the Zodiac Man woodcuts in these EModE almanacks in order to trace the development of said features throughout the sixteenth century. I was trying to look for patterns and diachronic development in the aforementioned categories. The results of my research pointed to a relationship between verbal and visual elements: the contents of the almanacks determined the visual themes presented in them. In terms of language choices (the use of English, French, or Latin) and linguistic features (e.g. astrological vocabulary) there were, however, few patterns or traces of development detectable during the time period.
To summarise a few interesting findings I made: many of the 48 almanacks that were analysed contained the same terminology in different languages (and often even inside the same specific almanack), highlighting some undecidedness in the choice of terms before the standardisation of the English language. It is also unclear whether certain printers used only specific woodcuts but there were certainly some styles of woodcuts more preferred than others. The themes and topics of the texts surrounding the illustrations also had an effect on what kind of a Zodiac Man image was used in the publication. For example, a certain type of image was preferred depending on whether the text was more informational or whether the image served more of an aesthetic purpose separate from the surrounding text.
Looking at the research process now I realise there is a lot more to look into when examining EModE printed almanacks: besides the Zodiac Man image there are many other interesting illustrations and features to be examined. Perhaps one could even write a doctoral dissertation in the field of Early Modern Graphic Literacies?
The author (MA) graduated in the Summer of 2023 and is currently doing smaller translation tasks as a freelancer along with her day job in customer service. She is currently considering postgraduate studies at the University.
Kaltiomaa, Saara. 2023. Analysing the Man of Signs: A Study on the Changes of the Linguistic Elements and the Contexts of the Zodiac Man Figure in Early Modern Almanacks (1537–1603). Master’s Thesis, Department of English, University of Turku. Available online: https://urn.fi/URN:NBN:fi-fe2023042438490.
Our EModGraL team and other philologists at the Turku Department of English will be strongly represented at the ICEHL this year. The 22nd International Conference on English Historical Linguistics takes place at the University of Sheffield, 3 – 6 July 2023. Below we will give a brief overview of our papers to be delivered at the conference. For the full abstracts, see the book of abstracts published on the conference website.
EModGraL research
The conference programme includes three papers discussing research done as part of the EModGraL project.
Vice-PI Mari-Liisa Varila will give a paper entitled ‘Captions and caption-like elements related to graphic devices in early modern English medical texts’. She analyses the relationship of the text and the graphic devices and identifies the different purposes that captions and caption-like elements served in medical texts, such as identifying the device or providing the reader with instructions.
The paper by Aino Liira and Wendy Scase (University of Birmingham) will focus on various table-like elements and the vocabulary surrounding them (title: ‘Tables, lists, rules and accounts: Tabular “graphic devices” in Early Modern English books’). In this paper, they take a closer look at items which have been tentatively placed under the category of ‘unclear tables’ in the EModGraL data collection process, and aim to find out how such graphic items were conceptualised by early modern authors and book producers.
Sirkku Ruokkeinen’s paper ‘“With diuers Tables annexed for the present making of your battells”: Paratextual framing of graphic devices in sixteenth-century military works printed in England’ discusses the use and framing of graphic devices in sixteenth-century works addressing military strategy and education. She particularly focuses on the title-pages and paratextual front matter of the books, where the graphic devices were advertised and discussed in order to promote the work.
Other research
The EModGraL team members and our colleagues at the English department are involved in several interesting research projects, and we decided to take the opportunity to introduce these as well.
Hanna Salmi will give a paper closely related to the EModGraL research interests. The title is ‘“I think my self obliged to place three Figures here together”: Framing graphic elements in 18th to 19th century dance manuals’. In this paper, she draws into focus an under-researched genre of dance manuals, which featured many kinds of graphic devices and visual notation. To shed light on the use of these graphic elements which supported verbal dance instructions, she examines how they were framed and explained to the reader.
Scribal practices are discussed in a joint paper by Peter Grund (Yale University) and Matti Peikola, entitled ‘Colonial orthographies: Uses of the ampersand in the legal documents from the Salem witch trials’. Their research reveals that there were clear differences in how the recorders at the Salem witch trials (1692–3) used the ampersand and the Tironian et (⁊), as opposed to the written-out and. They also show that several linguistic and extralinguistic factors played into this variation. Their paper is part of a broader project on the orthographic features of the witch trial documents.
Sara Pons-Sanz (University of Cardiff) and Janne Skaffari’s joint presentation ‘Orrm’s French- and Norse-Derived Terms’ is part of a workshop focusing on the Ormulum, a sermon collection from the late 12th century. In this paper, Janne looks at the French-derived words, many of which represent the lexical field of faith.
The research project ‘Between Science and Magic’ (@titaraproject; PI Mari-Liisa Varila) is represented at the conference by Ida Meerto, who presents some results of her PhD study in a paper entitled ‘Genre and Subject Matter in the Use of Words for Witches in Old English Prose’. She focuses on a selection of the most commonly occurring words, discussing how the word choice depends on the genre or register of the text but also on the temporal and geographical setting of the narrative.
We’re looking forward to an invigorating conference experience and many interesting discussions on the history of the English language!
Text: Aino Liira & the authors named Photo: Johanna Rastas
Dr Janne Skaffari is a senior lecturer at the Department of English, University of Turku. He joined the EModGraL team in August 2022. In this post, Janne tells us more about how the topic of graphic literacies features in his research and teaching.
Dr Skaffari looking at 17th and 21st century grammars. Photo: Mari-Liisa Varila
How does your previous work connect to graphic literacies?
I think it was when the English Department’s Pragmatics on the Page team started working on the interplay of the linguistic with the visual that I first saw how relevant and exciting the visual – and also graphic – dimension was. We organised a symposium and edited a book together, and I keep returning to all things visual when I research, for instance, written codeswitching in medieval manuscripts.
What is your role and your main area of research in EModGraL?
I am the ‘grammar guy’, so I work on 17th-century grammar books and their graphic devices. Describing grammatical structures often invites graphic support.
Does the theme of graphic literacies feature in your teaching?
I see and utilise figures and tables all the time when teaching descriptive grammar. The model we use in the second-year grammar course is corpus-based, so frequencies and register differences are often presented graphically in the textbook, and it often makes sense to draw the students’ attention to the figures and tables, not just to the descriptions and analyses written in prose. As I also supervise theses, I often recommend explicating classifications and frequencies by graphic means. Quantitative results are often much harder to follow it they appear in sentences rather than in tables.
Why is studying early graphic literacies important?
We often think that the visual aids and graphic presentations we see around us are a new thing, and if not a brand-new thing, at least not something that goes back more than a couple of generations. However, tables and other graphic elements were used centuries ago, in quite early printed books but also before the printing press, when texts were manuscript rather than printed. Although things change all the time, there is a lot that does not disappear, even if the technology changes.
Has the project given you new research ideas regarding graphic devices or graphic literacies?
There is a lot of visual information in the early modern grammar books that is not explained; the readers were apparently expected to understand how tabular layout, curly brackets and the information in and around them should be read and understood. I am curious about these literacy skills. I would also like to trace diachronically the particulars of how specific grammar topics, such as the system of personal pronouns, have been presented in books over centuries, all the way up to the present. This is an area where I can bring what I teach together with my research interests.
Calendar of saints (June). A medieval manuscript fragment, ca. 1340–1360, National library of Finland, F.m.VII.1. This Latin calendar, dating from the same period as the calendars studied by Peikola and Varila, has been used by the Dominican convent of Turku, Finland. Image via Doria (public domain).
Calendars were a specific type of table that was perhaps the most familiar to late medieval readers. They provided information about saints’ days and other liturgical feasts but also contained a variety of other kinds of information, often in a highly condensed form.
In their study, Peikola & Varila found differences between the contents and presentation of calendars in religious manuscripts vs those in e.g. astro-medical manuscripts. They suggest that these may be viewed as distinct subgenres, although they also found hybrids. Language choices reflected genre conventions and specialised functions, and calendars produced in the latter half of the period studied were more likely to be multilingual. Finally, the authors note that the potential influences of print technology on the generic properties of calendars should be examined in the future. This study is currently under preparation.
Peikola Matti & Mari-Liisa Varila. “Multimodal and Multilingual Practices in Late Medieval English Calendars”. In Multilingualism from Manuscript to 3D: Intersections of modalities from medieval to modern times, edited by Matylda Włodarczyk, Jukka Tyrkkö & Elżbieta Adamczyk, 93-118. New York: Routledge, 2023. DOI: 10.4324/9781003166634-6. (Open access)
Researcher mobility is an important part of academic life, although that “mobility” need not always be physical – as Mari wrote in her blog post in May, collaboration can take many forms.
This autumn term I was invited by our collaborator, Prof. Emer. Wendy Scase, to visit the University of Birmingham. She would mentor me during the 12-week visit and we would start working on a co-authored article. I would also spend a large part of my time in research libraries consulting early modern books for the project. Although travel restrictions have been lifted, the Covid-19 pandemic still has effects on daily life and some academic events are still being organised online. For these reasons, I followed my mentor’s advice and arranged to stay in London instead of Birmingham so that I would have easier access to research libraries.
I arrived in the UK on 1 September. In London, my weekly routine mainly consisted of days spent at the British Library. I typically reserved one or two days for working from home, which allowed me to participate in events and meetings via Zoom both in the UK and in Finland, as well as to take some time to organise my library notes and photos, to work on research articles, and so on. I also briefly visited the Wellcome Collection and the Cadbury Research Library at the University of Birmingham toward the end of my trip.
Some of the research seminars weren’t in full swing yet but I participated in both live and online meetings of the Centre for Reformation and Early Modern Studies (CREMS). I was invited to give a talk in mid-October. I’d like to thank my enthusiastic audience and the great questions and comments I received! The event took place via Zoom but the discussion was lively. In my talk, I gave a brief general introduction to the EModGraL project and then discussed some of my own research in more detail, including both solo articles and collaboration. The article project which was my main focus during this trip, in addition to my collaboration with Prof. Scase, revolves around handwritten annotation in books containing graphic devices. These were the kinds of books that I was looking for when working at the BL.
One of the CREMS seminar meetings was held at the Shakespeare Institute in Stratford-upon-Avon.
Not everything went as planned. The frequent rail strikes did not affect me as much as I’d feared, but I’m grateful that I decided to stay in London! However, I was meant to deliver another talk to a different seminar group, which had to be postponed to next year. It’s a pity as I was looking forward to an in-person event at Birmingham, but at least we can maintain the connections over Zoom. I did meet some colleagues over lunch or coffee in London and in Birmingham – many thanks to everyone involved! – and got to attend all three wonderful Panizzi lectures on medieval diagrams by Prof. Jeffrey F. Hamburger at the British Library.
It was a curious time to be in the UK – to think that during my brief visit of just under 3 months the country had two monarchs and three Prime Ministers! And if the political climate was somewhat turbulent, the actual weather was slow to change; it was exceptionally warm throughout the autumn, with sunny days well into November. The temperatures of some 10°C didn’t stop me from getting into a festive spirit toward the end of my trip as I visited a Christmas market in Birmingham and enjoyed a cup of mulled wine in Covent Garden. In the meanwhile, Finland had turned into a snowy Winter Wonderland and after an intensive research period it was lovely to return home in time for December. I had a lot of catching up to do and I’m now ready to wrap up the year.
On behalf of the EModGraL team, I wish everyone Happy Holidays and a Joyous New Year!
Turku Cathedral, 2 December 2022
Text and photos: Aino Liira | Twitter: @penflourished
We currently have two postdoctoral researchers working for the project. Sirkku Ruokkeinen started her research stint in July 2022. In this interview, she tells us more about her contribution to the project and her thoughts on graphic literacies.
Photo: Sirkku Ruokkeinen.
How did you first become interested in graphic literacies?
I have always been interested in liminal spaces, especially paratextuality. My interest lies in managing the reader, their expectations, interpretations, and the ways the text is used. The relationship between text and graphic elements is reminiscent of that between text and paratext. What is expected of the reader? What different ways of reading does the author prepare for? How are errors and subversive readings prepared for? How is the reader instructed?
What will be your main area of responsibility in EModGraL?
I will look into how graphic devices are used in paratextual material – whether they were used to promote the work, advance its sales, if the paratextual matter was used to instruct in their use. This analysis will contribute to an overview of the expectations book producers had relating to the graphic literacy levels of the English readership.
What is, in your opinion, the most challenging aspect of the project?
At this stage, given that I have only just worked at the project for a few months, choosing and refining topics of research seems most difficult. There is plenty that could be taken up for study.
Is there a specific domain or genre you look forward to investigating? Why?
I’m especially interested in seeing how the Playfair graphs1 (late 1700’s) and other new graphic elements were framed on title pages and other paratexts, how they were discussed and presented to the audiences. I’m curious to see if there was an expectation of understanding, especially if any of these graphs made it to texts which were intended for non-expert audiences.
Why is studying early graphic literacies important?
It informs us on the ways in which our thinking may have differed from that of late medieval and early modern readers. Models for representing information influence our thinking and understanding of the world.
Sirkku Ruokkeinen & Aino Liira | Twitter: @proemium, @penflourished
1. William Playfair (1759–1823) is considered the inventor of several types of statistical graphs, the pie chart among others.
Playfair’s 'The Commercial and Political Atlas' (3rd ed. 1801), with references for further reading, is available at: https://archive.org/details/PLAYFAIRWilliam1801TheCommercialandPoliticalAtlas/page/n75/mode/2up