Timosen väitöskirjan kansikuva on Ozun elokuvasta Varhainen kevät (Sōshun, 1956).
Yasujiro Ozu lukeutuu tunnetuimpiin japanilaisiin elokuvaohjaajiin, ja hänestä on tehty tutkimusta poikkeuksellisen paljon. Häntä on usein tarkasteltu formalistisesti, mikä on sinänsä ymmärrettävää, sillä Ozu oli tarkkojen kompositioiden ystävä ja suunnitteli teostensa visuaalisuuden huolellisesti. Timosen tavoitteena on kuitenkin lukea Ozun sodanjälkeistä tuotantoa laajemmassa kulttuurisessa kontekstissa ja pohtia, miten elokuvat kommentoivat, ja konstruoivat, sosiaalisia suhteita tilanteessa, jossa japanilainen yhteiskunta eli muutoksessa. Väitöstilaisuudessa Jaakko Seppälä ohjasi keskustelua taitavasti niihin tapoihin, joilla elokuvan kaltainen teos on suhteessa syntyaikaansa, mitä moniääninen teos kertoo ja millaisia tulkinnan vaihtoehtoja on. Seppälä ja Timonen kävivät mukaansa tempaavan keskustelun teemoista, jotka ovat kaiken taiteeseen kohdistuvan kulttuurihistoriallisen tutkimuksen ytimessä.
Usein Yasujiro Ozua kutsutaan erityisen japanilaiseksi ohjaajaksi. Väitöstilaisuudessa kävi hyvin ilmi, että tämä on pitkälti länsimaisen kulttuurin piirissä rakentunut yleistys. Ozun elokuvat olivat myös genre-elokuvia ja edustivat lajityyppiä, jossa oli tapana kuvata arkielämää, mutta jota länsimaissa on tunnettu vain vähän. Ozun elokuvat on usein nähty myös melankolisina, mutta väitöstilaisuudessa Timonen kutsui Ozua suureksi humoristiksi: Ozun elokuvissa on aina huumorin tuomaa inhimillisyyttä.
Väitöstilaisuuteen Arcanumin Aava-salissa osallistui 32 kuulijaa, jotka saivat hyvän johdattelun sekä elokuvan kulttuurihistorialliseen tutkimukseen että Yasujiro Ozun maailmaan. Ja ehdittiinpä käsitellä myös Ozun ehkä kuuluisinta otosta, elokuvassa Myöhäinen kevät (Banshun, 1949) nähtävää mystistä vaasia…
Olen Turun yliopistossa ensimmäisen vuoden kulttuurihistorian maisteriopiskelija, ja olen opiskellut nyt vuoden verran sivuaineena digitaalista kielentutkimusta ja ohjelmointia. Osallistuin tänä keväänä 2024 Helsingin digitaalisten ihmistieteiden hackathoniin. Kiinnostukseni digitaalisia ihmistieteitä ja tietokoneavusteisten menetelmien soveltamisesta on peräisin jo historian kandiopintojeni ajoiltani. Käytännössä digitaalisten ihmistieteiden kohdalla ”asiasta innostunut” lienee sopiva ilmaus kuvastamaan taitojani puhuttaessa Computer-Science- osaamistani. Olinkin todella positiivisesti yllättynyt päästyäni hackathoniin ja vielä haluamaani tutkimusryhmään, jonka tutkimusdata oli tapahtuman sponsorin Clarinin Euroopan eri maiden parlamenttien puheista koostuva ParlaMint-datasetti[1]. Vaikka muutkin hackathonin tämän kevään teemat[2] olivat erittäin kiinnostavia, laajan datasetin käyttäminen lähdeaineistona ja transformer- tekoälymallin hyödyntäminen käytännön tutkimustyössä oli minulle mieleinen aihepiiri ja omien opintojeni kannalta kaikkein hyödyllisintä oppimateriaalia.
Kulttuurihistorian opinnoissa omat kiinnostuksen kohteeni ovat liittyneet koulun ja koulutuksen historiaan. Oma mielenkiintoni digitaalisten ihmistieteiden mahdollisuuksista niin tutkimusmetodien kuin digitaalisten aineistojen kohdalla ja laitoksemme opintotarjonta ovat ohjanneet minut myös maisteriopinnoissa Kansalliskirjaston digitoitujen sanomalehtiaineistojen äärelle (Sanoma- ja aikakausilehdistön tutkimus- kurssi, sekä digitaalisen historian työpaja-kurssi). Koska tietokoneavusteisten menetelmien soveltaminen esimerkiksi suomenkieliseen materiaaliin vaatii käytännön ohjelmointitaitoja, oma maisterivaiheen ensimmäinen vuosi kului suurelta osin digitaalisen kielentutkimuksen sivuainekokonaisuuden parissa työskennellen. Nämä opinnot sisältävät muun muassa ohjelmoinnin perusteita, erilaisiin digitaalisen tekstidatan käsittelyyn suunnattujen ohjelmakirjastojen opettelua sekä tekoälyn alkeisiin perehtymistä.
Ilmoitin hakemuksessa, että toimisin mielelläni hybriditehtävissä, mutta ensimmäisen tapaamisen perusteella olin varma siitä, että saisin todennäköisesti toimia humanistin roolissa. Ryhmässämme oli useita kovatasoisia tietotekniikan osaajia ja heti alusta lähtien tutkimusaineiston käsittelyyn ehdotettiin ohjaamattoman koneoppimisen menetelmiä, kuten edellä mainittuja transformers-malleja. Vaikka minulla on takana vuoden verran tietotekniikan opintoja esimerkiksi Python-ohjelmoinnissa, digitaalisen kielentutkimuksen opinnoissa ja tekoälyn perusteissa, oli selvää, että esimerkiksi tekoälymallien arkkitehtuurin suunnittelussa oma osaamiseni ei olisi paljolti hyödyksi.
Valmistauduin itse tapaamiseen lukemalla ryhmänvetäjien suosittelemaa kirjallisuutta siitä, miten monella eri tavalla termi demokratia voidaan määritellä. Pyrin myös tutustumaan digitaalisten ihmistieteiden kirjallisuuteen, etenkin Jo Guldin The dangerious art of text mining oli omasta mielestäni erittäin hyödyllistä luettavaa. Koska politiikka ei ole ollut itselleni läheinen aihe opintojeni aikana, käytin myös paljon aikaa tutkiakseni poliittisen retoriikan merkityksiä.
Ryhmämme ideoi etätapaamisessa ennen hackathonia ja ensimmäisinä varsinaisina kontaktipäivinä tutkimuskysymyksiksi ”miten demokratiaa käytetään argumenttina” ja ”miten puhujan ominaispiirteet (esim. sukupuoli ja ikä) vaikuttavat puheiden tunteisiin”. Käytännössä tämä tarkoitti kahden luokittelevan tekoälymallin harjoittamista: Argumenttiluokittelija käyttäisi käsin annotoituja datasetistä tekstilouhittuja lauseita, joiden hakemiseen hyödynnettiin Clarinin NoSketch-engine korpustyökalua[3]. Tunnemalli taas olisi ohjaamattoman koneoppimisen projekti.
Jakauduimme kahteen työryhmään tutkimuskysymysten toteuttamiseen vaadittavien taitojen perusteella. Toinen suunnitteli tunnemallia ja toinen työsti argumenttiluokittelijaa. Tunnemalli sisälsi monimutkaisen teknisen toteutuksen laajan kielimallin valmistelussa ja itse harjoitusdatakorpuksen esikäsittelyssä, joten koin koko projektin kannalta hyödyllisemmäksi argumenttien parissa työskentelyn. Valitsimme kolme pääasiallista parlamenttiaineistoa: Ukrainan, Ison-Britannian ja Slovenian. Ehdotin aluksi Suomea mukaan, mutta käyttämämme ParlaMint-datasetin Suomen aineisto hylättiin suppean kokonsa takia. Suurin osa hackathonin ensimmäisistä päivistä kului siis annotointitehtävissä, ja omalla kohdallani Deep Translate -sivustoon tutustuessa Slovenian parlamenttiaineistoa selvittäessä.
Teimme annotointityötä pareissa käymällä läpi lauseita, joissa demokratia-sanan oikealla ja vasemmalla puolella oli sata kirjainta. Pääsin tekemään yhteistyötä tutkijatohtori, historioitsija Marko Miloševitsin kanssa. Tämä työskentely tuntui musertavan vaikealta, Marko joutui äidinkielenään Sloveniaa puhuvana selittämään minulle useita kohtia ja kestämään hidasta pakerrustani. Tästä huolimatta opin mielestäni todella paljon annotointityöskentelystä. Lopullinen luokittelutarkkuutemme oli yllättävän tarkka, noin 70 prosenttia myös vertailtaessa kaikkien ryhmässä työskennelleiden tarkkuutta keskenään. Annotointityö kesti lähes viikon verran ja oli hyvin intensiivistä koko ryhmällemme. Omalla kohdallani käytin myös vapaa-aikaani Slovenian lähihistorian opiskeluun, sillä etenkin ”vipuvarsi”-luokan kohdalla maan poliittisen kulttuurin ymmärtäminen helpotti luokittelua.
Malliksemme valikoitui XLM-R[4], jonka kyky hyödyntää useita eri kieliä oli juuri sopiva luokittelutehtäväämme. Harjoitimme omien annotointien, sekä niiden avulla GPT:n avustuksella tuotettujen esimerkkilauseiden avulla mallin tunnistamaan korpuksesta edellä mainittuja demokratiaan liittyvien lauseiden luokituksia. Malli oppikin tunnistamaan yllättävän hyvin eri luokkia, ja suuremmalla harjoitusdatasetillä olisi ollut mahdollista saavuttaa huomattavasti parempia tuloksia, sillä se ehti käydä harjoitusvaiheessa kaiken datan jatkuvasti paranevalla tarkkuudella:
X- akselilla siis ”askeleet”, läpikäyty data ja y- akselilla oppimisen laatu, eli mitä pienempi arvo, sitä paremmin malli on oppinut tunnistamaan luokitukset
Pystyimme siis käyttämään malliamme eri demokratiadiskurssien luokitteluun. Tulosten tultua aloimme käytännössä analysoimaan, mitä erilaiset luokittelut tarkoittivat. Olimme suunnitelleet myös toisen tunteita luokittelevan mallin, josta jouduttiin kuitenkin luopumaan alhaisen oppimisasteen takia ja tutkimusdatan käsittely tehtiin kokonaan argumenttiluokittelua hyödyntäen. Koska aikaa oli vähän, päädyimme tarkastelemaan dataamme lähinnä ”etäältä”, eli esimerkiksi aihemallinnuksella (”Topic modeling”) ja miten luokitukset jakautuivat aikavälillä. Tämä tarkoitti omalla kohdallani syvään päätyyn hyppäämistä, eli paneutumista luokiteltujen csv-tiedostojen visualisointiin.
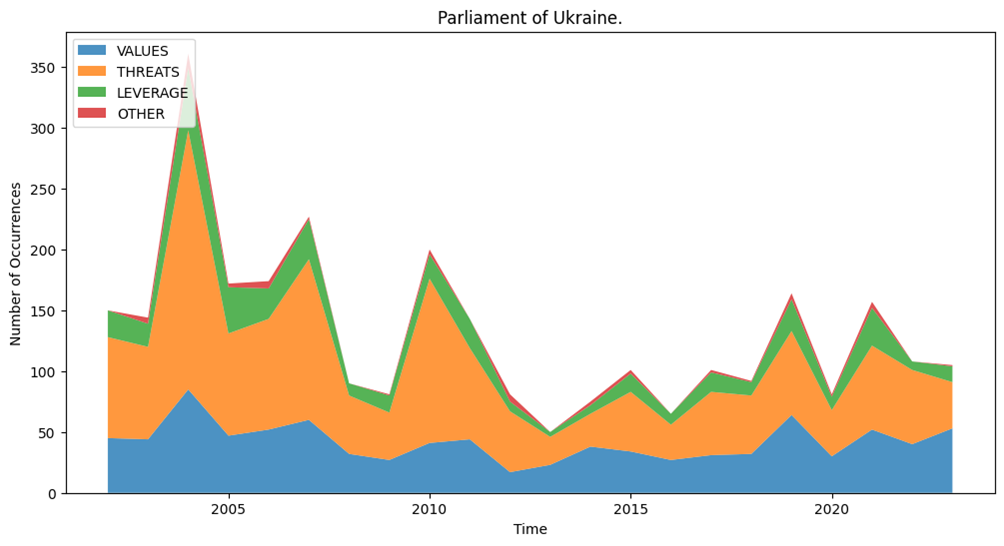
Torstain päätteeksi vaihdoimme sijaintimme yliopiston taukohuoneeseen viimeistelläksemme posterimme. Olen varma, että kaikki verenkierto kasvoistani loppui hetkeksi kokonaan, kun dosentti Jani Marjanen käski minut tuottamaan edellä mainitun pinotun kaavion ”steamgraphin” ajallisesta datastamme. Sain apua ryhmämme tietotekniikan eksperteiltä ja sain tehtyä useita alakirjastoja hyödyntävän koodinpätkän, jossa x-akseli kuvastaa kulunutta aikaa, ja y-akselilla näkyy ”pinottuna” eri argumenttiluokitusten esiintyminen.
Esimerkkinä Ukrainan parlamentin argumenttiluokituksien jakautuminen steamgraph- kaaviona
Sain onneksi apua ryhmämme tietotekniikan eksperteiltä tehtävän toteutukseen. Datan järjestäminen ajallisesti onnistui minulta vielä kohtalaisesti, mutta visualisointi ei olisi ollut mahdollista ilman opastusta.
Ensimmäisen rivin funktion tekemiseen sain apua Tuukka Puonnilta, syvät kiitokseni!
Voin siis lämpimästi suositella hackathonia digitaalisista ihmistieteistä kiinnostuneille opiskelijoille, sillä käytännön tutkimustyö eri menetelmien parissa selkeytti ainakin omalla kohdalla ajatuksen siitä, millaista tietoa humanisti voi saada irti esimerkiksi edellä mainitusta datasetin muodossa olevasta aineistosta, minkälaisia taitoja tähän prosessiin tarvitaan ja miten humanisti voi parhaiten ottaa osaa useita eri tieteenaloja yhdistäviin projekteihin. Annotointi on mielestäni tästä hyvä esimerkki: Henkilökohtaisesti koen, että luokittelutyön edistyminen johtui kokonaisvaltaisesta kehityksestä koko tutkimusprosessin aikana. Annotoinnin oppiminen oli kokonaisuus, joka edellytti luokkien määritelmien jatkuvaa tarkentamista, kommunikointia eri annotaattorien välillä ja aikaa ”virittäytyä” eri maiden parlamenttien retoriikkaan ja kulttuureihin. Vaikka käytimme Ukrainan ja Slovenian parlamenttien lauseiden kääntämiseen Deep Translate –sivustoa, kävimme keskustelua myös ryhmämme sisällä käännösten tarkkuudesta ja kulttuurisesta kontekstista, jolloin äidinkielenään ukrainaa ja sloveniaa puhuvat Artur Voit-Antal ja Marko olivat todella tärkeässä roolissa.
Toinen todella tärkeä oppi liittyy ohjelmointitaitoihin. Ajatellen nyt jälkeenpäin, miten käytin suuren osan viime lukuvuodesta digitaalisen kielentutkimuksen opintoihin, joiden parissa pääsin ”vierailemaan” myös tietojenkäsittelytieteiden ja tekoälyn perusteiden parissa, voin todeta, että kyseiset opinnot antoivat melko hyvät valmiudet hackathoniin, mutta niiden lisäksi syventyminen datatieteisiin olisi voinut olla hyödyksi. Kun pohdin ohjelmointitaitoja vaativia tehtäviäni hackathonin aikana, on kuitenkin painotettava, että tuotin lopulta määrällisesti hyvin vähän koodia. Lopulta visualisoinnit eivät vaatineet juurikaan ohjelmoinnin perusteiden taitoja, vaan tiettyjä apukirjastoja (esim. Pandas ja Matplotlib) ja datarakenteiden (esim. csv ja tsv) tuntemista. Käsittääkseni tämän kaltainen osaaminen historian ja tietojenkäsittelytieteiden rajamailla on yleensä hoidettu yhteistyössä eri tutkimusalojen välillä sen sijaan, että yksittäinen asiantuntija toteuttaisi kaiken aineiston keruusta koodin tuottamiseen ja tulosten analyysiin visualisointeineen. Vaikka yliopistojen tarjoamat ohjelmointikurssit on mielestäni laadukkaita ja hyödyllisiä taustaopinnoista riippumatta, kattavan monialaisuuden saavuttaminen digitaalisena ihmistieteilijänä on ainakin omien kokemuksien perusteella parhaiten saavutettavissa käytännön tutkimusprosessin, esimerkiksi hackathonin kaltaisten mahdollisuuksien aikana.
Pohdin myös, millainen kokonaisuus tietokoneavusteisuudesta kiinnostuneelle ihmistieteiden opiskelijalle olisi mahdollisimman sujuvasti omaksuttavissa ja tarpeeksi käytännönläheinen. Ohjelmoinnin perusteet johdattavat hyvin tietojenkäsittelytieteiden perusteisiin, mutta omissa toiveissani datatieteistä olisi myös saatavilla samankaltainen toteutus, kuten Tilastotieteen peruskurssi soveltajille, jossa käytäisiin läpi esimerkiksi korpustyyppisten aineistojen tilastollista mallintamista ja analyysia käytännön esimerkkien, kuten vaikka Pythonin Pandas -kirjaston avulla. Turun yliopiston digitaalisen historian työpajakurssi johdattaa käytännönläheisesti Galen digitaalisessa ympäristössä[5] eri analyysien, esimerkiksi aihemallinnuksen ja sentimenttianalyysin periaatteisiin helppokäyttöisillä työkaluilla. Edellä mainittu oma toivekurssini olisikin jatkoa työpajalle, mutta painotus olisi käytännön ohjelmoinnissa, eikä niinkään aputyökalujen käytössä. Työkalujen rajat tulevat vastaan etenkin useita eri kieliä sisältävien datasettien kohdalla, sillä suuri osa valmiista ohjelmista on suunniteltu englanninkielistä dataa varten ja omien kokemuksien perusteella tällaisten sovelluksien muokkaaminen esimerkiksi kielen osalta on usein hyvin työläs ja monimutkainen prosessi. Lisäksi ohjelmien toiminnan selittäminen akateemisen tutkimuksen avoimuuden ja luotettavuuden kohdalla saattaa olla hyvin ongelmallista tilanteessa, jossa tietokoneavusteisen työkalun algoritmia ei pysty selittämään, tai algoritmia ei ole edes mahdollista saada esille joko koodina tai dokumenttina.
Esimerkki Galen sentimenttianalyysin koodista, jonka toiminta on mielestäni melko hyvin dokumentoitu.
Ajatellen realistisesti historianopiskelijan opintotaipaletta yliopistolla ja huomioiden tietokoneavusteisten menetelmien runsauden en usko, että esimerkiksi kulttuurihistorian opiskelijalle on mahdollista räätälöidä kurssia, joka antaisi kaiken kattavat työkalut menneisyyden tutkimiseen tietokoneavusteisesti. Aiheesta kiinnostuneille paras tapa lienee lopulta haastaa itsensä tietotekniikan opinnoilla ja kokeilla mahdollisuuksien mukaan käytännön tutkimusprosessissa, mihin oma osaaminen vie. Tähän Hackathon oli mielestäni erinomainen tilaisuus: vaikka moni asia mitä ajattelin tekeväni ei toteutunut käytännössä ja osaamisen puolesta jouduin välillä nostamaan kädet ilmaan, lopputulema antoi runsaasti uusia taitoja sekä tulevia opintoja että maisteritutkinnon jälkeistä aikaa ajatellen.
Lopulta reitti historianopiskelijasta digitaaliseksi ihmistieteilijäksi on parhaiten kartoitettu oman kiinnostuksen mukaan. Hackathon osoitti, että näennäisen vähäiset taidot tietyllä osa-alueella eivät tarkoita automaattisesti olematonta roolia tutkimuksen kokonaisuuden kannalta. Samoin vertaisoppiminen yhdessä esimerkiksi datatieteen parissa rutiininomaisesti työskentelevien opiskelijoiden kanssa johti ainakin omalla kohdalla ripeään kehittymiseen edellä mainittujen visualisointien kanssa. Digitaalisten ihmistieteiden hallinta ja hyödyntäminen tarkoittaa kuitenkin pitkäjänteisyyttä esimerkiksi ohjelmoinnin perusasioiden hallinnassa, mikä ainakin itselle edustaa suurinta hyppyä tuntemattomaan, hyvin kauas lähes kaikista kandivaiheessa opituista taidoista. Kuitenkin tällainen loikka on mielestäni hyödyllinen sekä akateemisen osaamisen, että mahdollisten tulevien työelämätaitojen kannalta.
Johan Wahlsten on kulttuurihistorian opiskelija Turun yliopistossa. Blogiteksti on kirjoitettu osana digitaalisten ihmistieteiden hackathonin loppuraporttia kesällä 2024.
[4] Conneau, Alexis, et al. ”Unsupervised cross-lingual representation learning at scale.” arXiv preprint arXiv:1911.02116 (2019). Foxlee, Neil ‘Pivots and Levers: Political Rhetoric around “Capitalism” in Britain from the 1970s to the Present’, Contributions to the History of Concepts 13, no. 1 (2018): 75–99.
Foxlee, Neil ‘Pivots and Levers: Political Rhetoric around “Capitalism” in Britain from the 1970s to the Present’, Contributions to the History of Concepts 13, no. 1 (2018): 75–99.






{kind=link}